We build adaptive runtime systems that efficiently harness parallelism across diverse computing platforms while optimizing performance and energy.
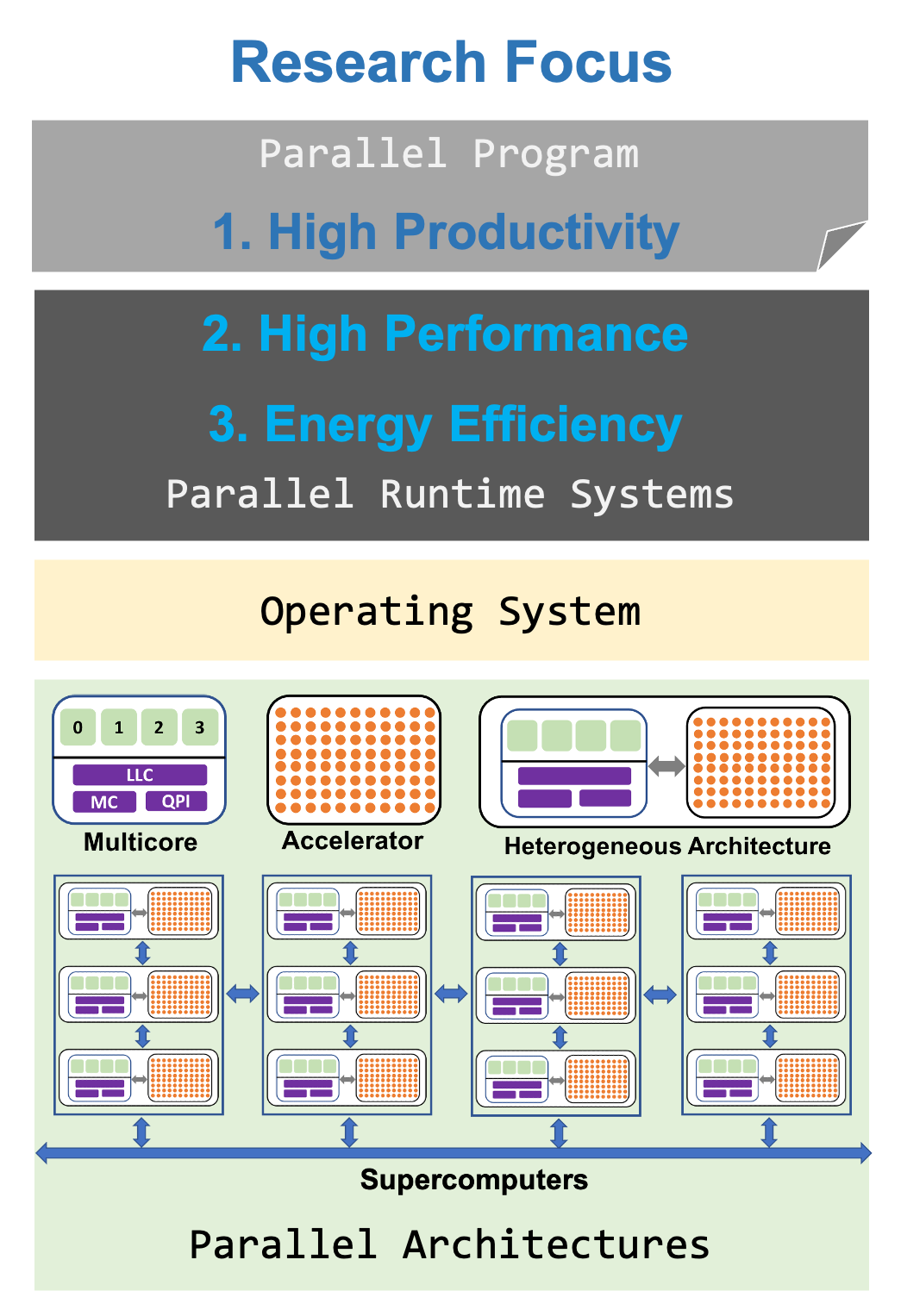
The computing landscape is undergoing a fundamental shift. Performance gains no longer come from faster processors, but from increasing parallelism and hardware diversity. Modern systems integrate many-core processors, complex memory hierarchies, and specialized accelerators, driven in large part by the demands of AI/ML workloads and exascale computing. This growing complexity makes efficient resource management increasingly challenging, requiring a careful balance between performance, energy efficiency, and programmer productivity.
Our research addresses these challenges by designing adaptive, hardware-aware runtime systems that dynamically respond to application behavior and system conditions. By bridging high-level programming abstractions with low-level hardware insights, we enable efficient execution across diverse platforms—from AI-driven workloads to large-scale exascale systems. Our goal is to deliver portable, high-performance, and energy-efficient execution that transparently exploits parallelism while reducing complexity for developers.
S. Kumar, V. Kumar, and S. Bhalachandra, "Power Scheduling for Maximizing Throughput and Fairness in Co-running Applications", in ACM Transactions on Architecture and Code Optimization (TACO), 2026.
Due to the significant cost associated with power consumption, hardware overprovisioning is widely used to cap processor power consumption and improve the average power utilization of servers in data centers and nodes in HPC clusters. However, uniformly capping power across sockets in multiprocessor servers can lead to performance degradation for co-running applications due to workload variability. Existing solutions primarily focus on cluster-level power management, making limited use of power scheduling within multi-socket servers or processor frequency scaling to regulate power consumption under power constraints.
This paper introduces Fulcrum, a novel power management library for co-running parallel applications on multi-socket, multi-core servers, independent of the underlying parallel programming model. Fulcrum dynamically redistributes power on a power-constrained multi-socket server to maximize throughput and fairness for co-running applications without requiring prior knowledge of application characteristics. Our results show that Fulcrum improves system throughput (geometric mean) by 26.3% under low power caps and by up to 5.3% under higher power caps, while delivering power efficiency improvements of 27.7–8.4% at the respective power caps.
V. Kumar, and S. Kumar, "Method and System for Bidirectional Power Scheduling in Multiprocessor Environments", Indian Patent Application No. 202511096593, Published December 2025.
Embodiments of the disclosure describe a bidirectional power scheduling method for a multiprocessor. The method includes assigning a predefined Power Capping (PCAP) to a plurality of sockets of the multiprocessor. The predefined PCAP indicates a maximum power consumption limit for each socket while at least one application is utilized on at least one socket among the plurality of sockets. The method further includes monitoring a Central Processing Unit (CPU) utilization periodically across each socket after assigning the predefined PCAP. The method further includes determining whether the at least one socket among the plurality of sockets requires a modification of the assigned predefined PCAP during the monitoring. The method further includes dynamically redistributing the assigned predefined PCAP bidirectionally among the plurality of sockets in response to determining that the at least one socket among the plurality of sockets requires modification.
V. Jain, V. Parashar, V. Kumar, and C. Sur, "Energy-Aware Runtime Resource Harmonizer for Co-running Applications", in 32nd IEEE International Conference on High Performance Computing, Data, and Analytics, Hyderabad, India, December 2025.
Modern multiprocessor systems, with their abundance of cores and sockets, make the simultaneous execution of multiple applications essential for maximizing system utilization. However, the performance and energy efficiency of co-executing applications are highly sensitive to thread placement, core allocation, and both core and uncore frequency settings. Existing dynamic resource allocation solutions often rely on model-based approaches, require intrusive modifications to the parallel runtime, or lack a unified framework.
This paper presents Harmonizer, a novel dynamic resource optimization library for co-running applications on multiprocessor systems to improve overall system throughput and energy efficiency. Our results show that Harmonizer reduces energy consumption by 8.8% to 35% (20.5% geometric mean) and improves throughput by 4.8% (geometric mean) compared to the default Linux scheduler. Compared to two state-of-the-art approaches, it achieves up to 28.6% energy savings and 15.8% higher throughput.
Vivek Kumar, "Teaching Task-Based Parallel Programming with a Runtime Systems-Aware Perspective", SC25-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, St. Louis, MO, USA, November 2025.
Conventional parallel programming using explicit multithreading over modern multicore processors imposes significant complexity in organizing and balancing work across threads. Task-based models simplify parallel programming using runtimes that handle task scheduling and resource management, improving scalability and reducing developer effort.
This paper presents the structure and experiences of teaching the Parallel Runtimes for Modern Processors course (PRMP) at IIIT Delhi. Students implement a basic task-based parallel programming model in the async–finish style, then gradually improve both the model and the runtime. We conclude with a qualitative and quantitative evaluation of three offerings of PRMP, showing significant improvement in students' understanding of parallel program execution.
S. Kumar, and V. Kumar, "KarmaPM: Reward-Driven Power Manager", in 31st International European Conference on Parallel and Distributed Computing, LNCS, Springer, Dresden, Germany, August 2025.
Hardware overprovisioning is a widely used technique to improve the average power utilization of computing systems by capping the processor's power consumption. However, applying a uniform power cap across multiprocessor system sockets can significantly impact co-running applications due to workload variations.
This paper introduces KarmaPM, a novel power management library for co-running applications on multiprocessor systems, based on application power donation karmas. KarmaPM dynamically redistributes power bidirectionally across sockets to improve overall system throughput. Our results show that KarmaPM improved system throughput (geometric mean) by 13.2% at lower power caps and 6.6% at higher power caps, with improvements of 12.5% and 4.4% over state-of-the-art approaches.
M. Bhatt, T. Chauhan, R. Agrawal, M. Kumar, V. Kumar, and S. Sircar, "Elastoinertial Stability Analysis and Structure Formation in Viscoelastic Subdiffusive Pipe Flow", in Physics of Fluids, 2024.
H. Saini, V. Kumar, and T. Chakraborty, "Energy Efficient Permanence-based Community Detection Algorithm", in Concurrency and Computation: Practice and Experience, 2024.
Detecting an accurate community structure is a crucial task in network analysis. This paper introduces Amoeba, a task parallel implementation of a permanence-based community detection algorithm designed for multicore processors. It uses dynamic tasking to schedule inherent irregular computation, and can dynamically adapt the total number of parallel threads for improved energy efficiency. Amoeba achieves a geometric mean speedup of 15.3× over its sequential implementation and energy savings of 12.4% over its non-adaptive implementation.
S. Kumar, V. Kumar, and S. Bhalachandra, "Energy-Efficient Execution of Multicore Parallel Programs under Limited Power Budget", in 29th IEEE International Conference on High Performance Computing, Data, and Analytics Student Research Symposium, Bangalore, India, December 2022.
V. Kumar, "Teaching High Productivity and High Performance in an Introductory Parallel Programming Course", in Proceedings of the 28th International Conference on High Performance Computing, Data and Analytics Workshop (HiPCW), Bangalore, India, December 2021.
Multicore processors are ubiquitous. In this paper, we present the structure and experience of teaching the Foundations of Parallel Programming course (FPP) at IIIT Delhi using a task-based parallel programming model, Habanero C/C++ Library (HClib). FPP covers a wide breadth of topics emphasizing both high productivity and high performance, offered in the spring semester for undergraduate and postgraduate students since 2017.
S. Kumar, A. Gupta, V. Kumar, and S. Bhalachandra, "Cuttlefish: Library for Achieving Energy Efficiency in Multicore Parallel Programs", in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC'21), St. Louis, MO, USA, November 2021.
A low-cap power budget is challenging for exascale computing. This paper proposes Cuttlefish, a programming model oblivious C/C++ library for achieving energy efficiency in multicore parallel programs running over Intel processors. An online profiler periodically profiles model-specific registers to discover a running application's memory access pattern. Using a combination of DVFS and UFS, Cuttlefish dynamically adapts the processor's core and uncore frequencies, achieving geometric mean energy savings of 19.4% with a 3.6% slowdown.
V. Kumar, "PufferFish: NUMA-Aware Work-stealing Library using Elastic Tasks", in 27th IEEE International Conference on High Performance Computing, Data, and Analytics, Pune, India, December 2020.
This paper presents PufferFish, a new async–finish parallel programming model and work-stealing runtime for NUMA systems that provide a close coupling of the data-affinity hints provided for an asynchronous task with the Hierarchical Place Trees (HPTs) in HClib. PufferFish introduces Hierarchical Elastic Tasks (HET) that improve locality by shrinking to run on a single worker or puffing across multiple workers depending on work imbalance. On a 32-core NUMA AMD EPYC processor, PufferFish achieves a geometric mean speedup of 1.5× over HPT and 1.9× over random work-stealing in CilkPlus.
V. Kumar, A. Tiwari, and G. Mitra, "HetroOMP: OpenMP for Hybrid Load Balancing Across Heterogeneous Processors", in 15th International Workshop on OpenMP, LNCS, Springer, Auckland, New Zealand, September 2019.
This paper proposes HetroOMP, an extension of the OpenMP accelerator model supporting a new hetro clause that enables computation to execute simultaneously across both host and accelerator devices using standard tasking and work-sharing pragmas. We implemented a proof-of-concept work-stealing HetroOMP runtime for the TI Keystone-II MPSoC (4 ARM CPUs + 8 DSP processors), achieving a geometric mean speedup of 3.6× compared to using only the OpenMP accelerator model.
V. Kumar, "Featherlight Speculative Task Parallelism", in 25th International European Conference on Parallel and Distributed Computing, LNCS, Springer, Göttingen, Germany, August 2019.
This paper proposes Featherlight, a new programming model for speculative task parallelism that satisfies the serial elision property and doesn't require any task cancellation checks. We show that Featherlight improves productivity through a classroom-based study. Our task cancellation technique exploits runtime mechanisms in managed runtimes and achieves a geometric mean speedup of 1.6× over the popular Java Fork/Join framework on a 20-core machine.
M. Grossman, V. Kumar, N. Vrvilo, Z. Budimlic, and V. Sarkar, "A Pluggable Framework for Composable HPC Scheduling Libraries", in Proceedings of IEEE International Parallel and Distributed Processing Symposium Workshops, Orlando, Florida, USA, May 2017.
This paper presents HiPER (a Highly Pluggable, Extensible, and Re-configurable scheduling framework for HPC), a pluggable API framework on top of a "generalized work-stealing" runtime to achieve composability of communication, accelerator, and other HPC libraries. HiPER enables cooperation of discrete software frameworks within a single process and demonstrates programmability improvements and performance improvements over hand-optimized benchmarks through unified and asynchronous scheduling.
V. Kumar, K. Murthy, V. Sarkar, and Y. Zheng, "Optimized Distributed Work-Stealing", in 6th International Workshop on Irregular Applications: Architectures and Algorithms (IA3), Salt Lake City, Utah, USA, November 2016 (co-located with SC16).
This paper presents SuccessOnlyWS, a novel load-aware distributed work-stealing strategy in HabaneroUPC++ that overcomes failed steal attempts by introducing a new policy for moving work from busy to idle processors. Evaluated on up to 12,288 cores of Edison (CRAY-XC30), SuccessOnlyWS provides performance improvements up to 7% over the baseline approach.
V. Kumar, J. Dolby, and S. M. Blackburn, "Integrating Asynchronous Task Parallelism and Data-centric Atomicity", at The 13th International Conference on Principles and Practices of Programming on the Java Platform, Lugano, Switzerland, August 2016.
This paper presents five Java annotations for achieving asynchronous task parallelism and data-centric concurrency control, allowing use of a highly efficient work-stealing scheduler. Evaluated by refactoring classes from existing multithreaded open source projects, our annotations significantly reduce programming effort while achieving performance improvements up to 30% compared to conventional approaches.
M. Grossman, V. Kumar, Z. Budimlic, and V. Sarkar, "Integrating Asynchronous Task Parallelism with OpenSHMEM", at The 3rd workshop on OpenSHMEM and Related Technologies, Baltimore, Maryland, USA, August 2016.
This paper introduces AsyncSHMEM, a PGAS library that integrates OpenSHMEM with a thread-pool-based work-stealing runtime. AsyncSHMEM makes OpenSHMEM more adaptive by taking advantage of asynchronous computation to hide data transfer latencies, interoperate with tasks, improve load balancing, and improve locality. Experiments on the Titan supercomputer show AsyncSHMEM is competitive for regular workloads and significantly outperforms OpenSHMEM+OpenMP on event-driven applications.
V. Kumar, A. Sbirlea, Z. Budimlic, D. Majeti and V. Sarkar, "Heterogeneous Work-stealing across CPU and DSP cores", at The 19th International Conference on High Performance Extreme Computing, Waltham, MA, USA, September 2015.
This paper presents HC-K2H, a programming model and runtime for the TI Keystone II Hawking platform (4 ARM CPUs + 8 DSP processors). We design a hybrid work-stealing runtime allowing tasks to be created and executed on both ARM and DSP, with seamless synchronization regardless of which processor runs them. Task-parallel benchmarks on a Hawking board show excellent scaling compared to sequential single-ARM implementations.
V. Kumar, Y. Zheng, V. Cave, Z. Budimlic and V. Sarkar, "HabaneroUPC++: a Compiler-free PGAS Library", at The 8th International Conference on Partitioned Global Address Space Programming Models, Eugene, Oregon, October 2014.
This paper introduces Habanero-UPC++, a compiler-free PGAS library that supports tight integration of intra-place and inter-place parallelism. Built on UPC++ and HClib, it uses C++11 lambdas to avoid compiler support while retaining syntactic convenience. Evaluated using two benchmarks scaled up to 6,000 cores, the library demonstrates significant programmability and performance benefits.
V. Kumar, S. M. Blackburn and D. Grove, "Friendly Barriers: Efficient Work-Stealing With Return Barriers", at The 10th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, Salt Lake City, Utah, March 2014.
This paper addresses dynamic overheads in work-stealing, which occur each time a steal takes place and are dominated by introspection of the victim's stack. We exploit low-overhead return barriers to reduce dynamic overhead by approximately half, resulting in total performance improvements of as much as 20%. Because we attack overheads directly due to stealing, we improve the scalability of work-stealing applications.
V. Kumar, D. Frampton, S. M. Blackburn, D. Grove, and O. Tardieu, "Work-Stealing Without The Baggage", in Proceedings of the 2012 ACM SIGPLAN Conference on Object-Oriented Programming Systems, Languages & Applications (OOPSLA 2012), Tucson, AZ, October 2012. (selected for SIGPLAN Communications of ACM Research Highlights, 2013)
This paper identifies key sources of overhead in work-stealing schedulers and presents two significant refinements. Compared to orthodox sequential Java, our fastest design has an overhead of just 15%. By contrast, fork-join has a 2.3× overhead and the prior system has a 4.1× overhead. These results and our insight into overhead sources give further hope to an already promising technique for exploiting increasingly available hardware parallelism.
V. Kumar and S. M. Blackburn, "Faster Work-Stealing With Return Barriers", at The 6th workshop on Virtual Machines and Intermediate Languages (VMIL 2012), Tucson, AZ, October 2012.
This paper identifies the overhead associated with managing work-stealing related information on a victim's execution stack and presents the design of using return barriers to reduce these overheads. Compared to our prior design, we reduce overheads by as much as 58% on classical work-stealing benchmarks.
V. Kumar, D. Frampton, D. Grove, O. Tardieu, and S. M. Blackburn, "Work-Stealing by Stealing States from Live Stack Frames of a Running Application", at X10'11 Workshop collocated with PLDI 2011, San Jose, CA, June 2011.
This paper proposes allowing thieves to extract state directly from within stack frames of the producer, using state-map information provided by a cooperative runtime compiler. This avoids stack-allocating state objects and drives down the cost of making state available for stealable work items. We discuss our design and preliminary findings inside the X10 work-stealing runtime and Jikes RVM.

Assistant Professor, IIIT-Delhi

PhD candidate (Google PhD Fellowship)
Maximizing throughput and fairness in power-constrained systems






















M.Tech

M.Tech

B.Tech

B.Tech

B.Tech

B.Tech

B.Tech

B.Tech

B.Tech

B.Tech

B.Tech

M.Tech

B.Tech

B.Tech

B.Tech

B.Tech

B.Tech

B.Tech

M.Tech

M.Tech
Computing hardware is becoming more and more complex. Today and in the foreseeable future, performance will be delivered principally by increased hardware parallelism. Modern multicore processors scale to over one hundred cores, have wide vector units, maintain a complex memory hierarchy and even share the memory with accelerators such as GPU. Conventional programming models using threads impose significant complexity to organize code into multiple threads of control and balance work amongst threads. This course introduces the design and implementation of such a parallel runtime and explores the challenges in achieving performance and energy efficiency over modern processors. Offered at IIIT Delhi for undergraduate and postgraduate students.
Learn MoreMulticore processors are now universal, from mobile devices to supercomputers. Achieving high performance and energy efficiency on these architectures requires both a deep understanding of parallel programming models and the runtime systems that underpin them. This course covers task parallelism, data parallelism, loop parallelism, and synchronization, alongside the design of runtime systems that schedule and manage parallel work. Topics include work-stealing schedulers, NUMA-aware runtimes, user-level threading, memory consistency, cache coherency, SIMD vectorization, GPU computing, and power management. Offered at IIIT Delhi for undergraduate and postgraduate students.
Learn MoreThe CSEDU program is for teachers of Computer Science in both Engineering and non-Engineering disciplines. The Advanced Programming module prepares participants to build programs using an object-oriented approach, reusable code design, test-driven development, and pattern-oriented design. Topics include OOP paradigm, classes and objects, interfaces, inheritance, polymorphism, defensive programming, unit testing, design patterns, multithreading, event-driven programming, and tools for plagiarism detection.
Learn MoreMulticore processors are ubiquitous. It is an unavoidable consequence of the breakdown of Dennard scaling, which has put a stop to hardware delivering ever faster sequential performance. FPP introduces the fundamentals of parallel programming, covering both traditional approaches and new advancements. A key aim is to provide hands-on knowledge on parallel programming by writing parallel programs in different programming models. Offered in the spring semester at IIIT Delhi for undergraduate and postgraduate students.
Learn MoreThe Advanced Programming course is a successor to the Introduction of Programming course. The main goal is to prepare students for building large-scale programs with multiple functional components. The course uses Java to introduce concepts of object orientation, reusable code design, test-driven development, programming to an API, and pattern-oriented program design. Students develop large application programs starting from a well-defined application design.
Learn MoreOperating Systems is a core course for second-year undergraduate students at IIIT Delhi. An operating system serves as the fundamental interface between a computer's hardware and its users, responsible for managing resources, coordinating activities, and enabling efficient sharing of system components. The course is structured into two complementary components: theory (covering foundational concepts, design principles, and internal workings of modern OSes) and programming (hands-on implementation of core OS functionalities).
Learn MoreOur lab has an immediate opening for a PhD candidate to conduct research on energy-efficient GPU computing. In this project, we aim to develop runtime solutions for GPUs to reduce carbon emissions and energy usage without compromising overall performance of GPU-centric applications such as deep learning frameworks and LLMs. Interested candidates must have experience and proficiency in Python/C/C++ and strong academic performance in undergraduate-level computer science courses.
Apply Now